| § | библиотека – мастерская – | Помощь Контакты | Вход — |
Татарова Г.Г. Методология анализа данных в социологии (введение) /Учебник для вузов. —— М.: NOTA BENE, 1999. — 224 с.
Стр. 172 У нас с вами есть одномерное распределение какого-то признака. Напоминаем, что под признаком понимаем как отдельно взятый эмпирический индикатор (наблюдаемый признак), так и производный от эмпирических индикаторов показатель. Пусть таковым признаком будет удовлетворенность учебой (У). Распределение этого признака можем интерпретировать следующим образом. Есть значения признака (различные степени удовлетворенности учебой), и есть вероятности этих значений (относительные частоты в долях или частости). А, точнее, оценки вероятности, полученные по выборке. Все, что рассчитывается по выборочной совокупности, называется оценками истинных (существующих для изучаемой генеральной совокупности) значений. Разумеется, социолог может опускать термин «оценка», если понимает, о чем идет речь. Для простоты мы будем поступать так же. Итак, наши вероятности P0j равны маргинальным частотам по столбцам (именно они соответствуют признаку (У) ¾ удовлетворенность учебой), деленным на общее число опрошенных студентов-гуманитариев (n00). В виде формулы это выглядит так:
Эти вероятности можно интерпретировать как вероятности статистического предсказания (У). Мы же их получили по «хорошей» выборке. Поэтому если из нашей изучаемой генеральной совокупности студентов-гуманитариев случайно выберем некоторого студента, то вероятность того, что у этого случайного студента окажется максимальная удовлетворенность учебой, очень мала. Это потому, что по выборке она была равна всего лишь 0,05. Вероятность «отгадать» все остальные варианты удовлетворенности учебой тоже невелика ибо они, как видите, не больше, чем 0,3. При этом само понятие «вероятность» можно трактовать на уровне обыденного сознания. Только в повседневной жизни вам обычно говорят, например, «вероятность того, что у меня завтра будет плохое настроение для прогулки, равна 90%» или «вероятность того, что я завтра приду к тебе в гости, меньше 50%» или «вероятность нашей возможной встречи «фифти - фифти» (50 на 50)». И вы всегда понимаете, что сие означает. При этом такие суждения вы интерпретируете не столько количественно, сколько качественно. А в математических формулах пользуются не процентами для оценки вероятности, а долями ¾ частостями — и, соответственно, вероятность принимает вполне конкретное значение из интервала от 0 до 1. |
Реклама
|
||
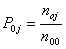 . Тогда, по приведенной ниже таблице 3.5.1 (это та же таблица сопряженности, с которой мы постоянно работаем), вероятности пяти степеней удовлетворенности учебой равны:
. Тогда, по приведенной ниже таблице 3.5.1 (это та же таблица сопряженности, с которой мы постоянно работаем), вероятности пяти степеней удовлетворенности учебой равны: